Uke 14 – Pandas examples¶
Obs
pandas er et eksternt bibliotek som vi må installere først i terminalen:
python -m pip install --user pandas
Hvis dette ikke fungerer så kan du prøve å kjøre denne koden:
install.py, som prøver å finne den riktige versjonen til Python med:
import sys
print(sys.executable)
Denne gangen skal vi se på Pandas-biblioteken, med det samme datasettet vi har brukt før.
Pandas er en veldig nyttig bibliotek til dataanalyse, som gjør det enkelt å få til mange av de vanlige ting man vil gjøre. Mer detalj finnes i introduksjonen her:
* https://pandas.pydata.org/docs/getting_started/overview.html
* https://pandas.pydata.org/docs/getting_started/intro_tutorials/index.html
Akvakultur¶
Last inn datasettet¶
FIlen er det samme som før: Akvakulturregisteret.csv.
Fra instructions on opening files
ser vi at vi bør bruke read_csv. Første forsøket er
import pandas as pd
akva = pd.read_csv('Akvakulturregisteret.csv')
print(akva.columns)
Flere ting går feil her: vi må fortelle pandas om at filen bruker ; som separator, og at
filen er kodert som iso-8859-1. Også er det litt uvanlig at informasjon
om kolonnenavn finnes i rad 1, ikke 0. La oss legge til alt dette:
import pandas as pd
import matplotlib.pyplot as plt
akva = pd.read_csv(
'Akvakulturregisteret.csv',
delimiter=';',
encoding='iso-8859-1',
header=1
)
print(akva.columns)
print(akva)
Det ser ut som at det fungerer allerede. Sammenlignet med CSV-modulen har vi mye mer informasjon inni
pandas-dataframet akva. Kolonnenavn ble satt automatisk, og vi kan skrive ut
ulik informasjon med f.eks:
print(akva['ART'])
print(akva['POSTSTED'].min(), akva['POSTSTED'].max())
Slicing og filtrering fungerer slik som vi så med numpy:
filt = (akva['ART'] == 'Laks')
print(akva[filt])
Plotting¶
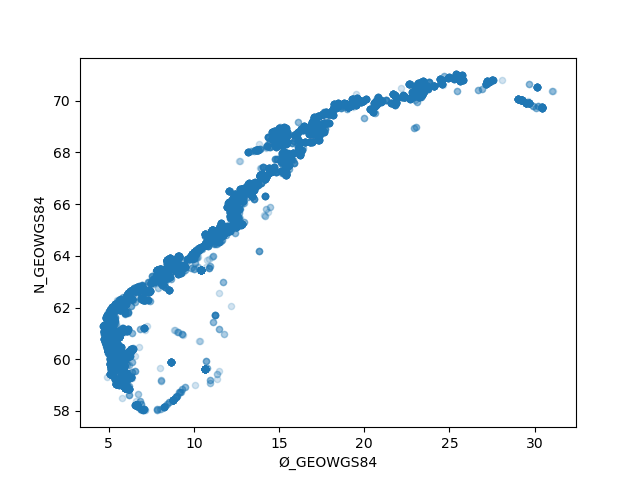
La oss se på visualisering. Tutorial on plotting er veldig nyttig. Det ser ut at vi kun trenger en linje til, for å få en scatterplot til alle posisjoner:
import pandas as pd
import matplotlib.pyplot as plt
akva = pd.read_csv(
'Akvakulturregisteret.csv',
delimiter=';',
encoding='iso-8859-1',
header=1,
)
print(akva)
print(akva.columns)
akva.plot.scatter(x='Ø_GEOWGS84', y='N_GEOWGS84', alpha=0.2)
plt.show()
Oppgavene fra CSV-kapittel¶
De ulike dataanalyse-oppgavene vi så tidligere kan enkelt gjøres med pandas:
Telle opp ulike arter (ART, column 12). Googling count categories in pandas foreslår
value_counts():print(akva['ART'].value_counts())
Plotte kun de som oppdrar Laks. Her kan vi bruke filtere:
laks = akva[ akva['ART'] == 'Laks' ] laks.plot.scatter(x='Ø_GEOWGS84', y='N_GEOWGS84', alpha=0.2))
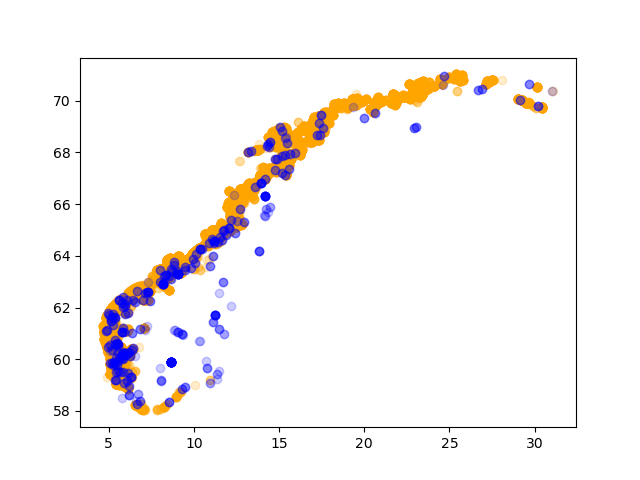
Plot FERSKVANN i en farge og SALTVANN in en annen (VANNMILJØ, column 20). Igjen bruker vi filtere. Scatter plots vi bruker her er vanlige matplotlib plots, ikke de som kommer direkte fra pandas. Vi ser hvor enkelt det er å kombinere disse ulike bibliotekene:
import pandas as pd import matplotlib.pyplot as plt akva = pd.read_csv( 'Akvakulturregisteret.csv', delimiter=';', encoding='iso-8859-1', header=1, ) salt = akva[ akva['VANNMILJØ'] == 'SALTVANN' ] plt.scatter(x=salt['Ø_GEOWGS84'], y=salt['N_GEOWGS84'], c='orange', alpha=0.2) fersk = akva[ akva['VANNMILJØ'] == 'FERSKVANN' ] plt.scatter(x=fersk['Ø_GEOWGS84'], y=fersk['N_GEOWGS84'], c='blue', alpha=0.2) plt.show()
Flere eksempler¶
Below are a few examples (in English) of using pandas, matplotlib, and numpy to deal with large datasets:
Summary¶
Pandas er ett av de flestbrukte dataanalyseverktøy i realfag, og tilbyr mye mer enn det vi kan vise i en innføringsforelesning til Python. Om du synes det er nyttig for deg, start på pandas-nettsiden og følg med i de ulike tutorials, med tanke på dine egne datasett.
Oppgaver¶
Obs
Det er den siste oppgaven for dette semesteret! Du må gjøre begge oppgavene for å få full kreditt for denne uken. Det kommer igen auto-testene denne uken.
For de som har lyst til å programmere mer i løpet av sommeren så finnes det en adventskalender med programmeringsoppgaver: Advent of Code. Det er ulike vanskelighetsgrad på de ulike oppgavene, men du kan prøve og se hvor mange du kan løse. Om du blir med: lykke til!
Oppgave 1¶
I denne oppgaven skal vi jobbe med datasettet VIK_sealevel_2000.txt som inneholder målinger av havnivå for hver time av året 2000. Det er valgfritt å bruke pandas for å løse denne oppgaven.
I filen uke_14_oppg_1.py gjør du følgende:
- a) skriv en funksjon
read_datasom tar inn et filnavn og returnerer en pandas dataframeder den første kolonnen (index) skal ha navnet
dateog innholderdatetime. De andre kolonnene skal ha navnyear month day hour sealevel. Du kan anta at filen har samme format somVIK_sealevel_2000.txt.Obs
TIPPS: her er det lurt å se på read_csv og to_datetime
Eksempelkjøring for pandas dataframe. Obs!
hourmå være 0-23, ikke 24!>>> print(data.head()) year month day hour sealevel date 2000-01-01 00:00:00 2000 1 1 0 335 2000-01-01 01:00:00 2000 1 1 1 336 2000-01-01 02:00:00 2000 1 1 2 338 2000-01-01 03:00:00 2000 1 1 3 341 2000-01-01 04:00:00 2000 1 1 4 347b) skriv en funksjon
plot_monthssom tar inn en dataframe formatert som i a) og plotter en graf som viser gjennomsnittlig havninvå for hver måned. Gi grafen og aksene passende navn, og velg noen fine farger.c) skriv en funksjon
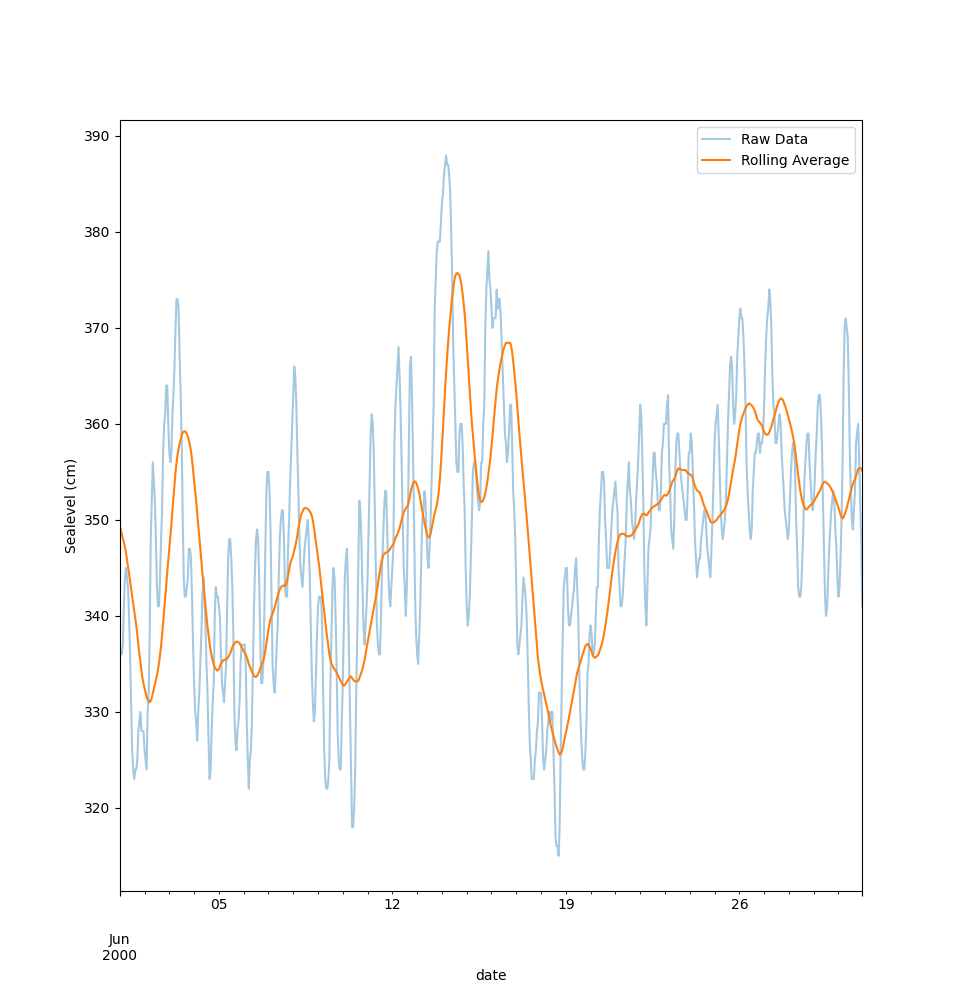
plot_rolling_averagesom tar inn en dataframe formatert som i a).Funksjonen skal plotte havninvået for juni måned både direkte og som et glidende gjennomsnitt (rolling average).
Velg periode for det glidende gjennomsnittet selv. Grafen kan f.eks se sånn her ut:
Lagre plot med navnet
uke_14_oppg_1.pngog laste opp filen.Obs
TIPPS: se på rolling i pandas dokumentasjonen.
Oppgave 2 - Airport Codes¶
I denne oppgaven skal vi jobbe med airport codes. Følg oppgaveinstruksjonene på den følgende siden og lagre koden i filen uke_14_oppg_2.py.