Uke 8 — Problemløsning¶
Eksempler¶
Vi skal se på noen eksempler på hvordan man kan løse problemer ved hjelp av programmering. Fokusen denne uken ligger på identifisering av programmeringsstrukturer: if-setninger, for-løkker, etc.
Eksempel 1¶
Først skal vi jobbe sammen i grupper for å løse oppgaven i denne lille teksten:
Du jobber med et prosjekt hvor du må sortere en gruppe mennesker i to grupper: eksperter og ikke-eksperter, basert på et egenrapportert nivå av kompetanse i et biologitema fra 0 (ikke kunnskapsrik) til 5 (ekstremt kunnskapsrik). De som har sagt nivå 4 eller 5 burde bli plassert i gruppen «eksperter» mens resten burde bli plassert i gruppen «ikke eksperter.»
Beskriv for hverandre hvordan du vil løse oppgaven med programmering. Hva er forventet input? Hva skal du skrive ut? Hvor vil du bruke for-løkker, if-setninger eller funksjoner?
Det er nok å skissere en løsning, du trenger ikke å programmere noe.
Eksempel 2¶
Vi skal løse Problem 2 fra projecteuler.net:
Each new term in the Fibonacci sequence is generated by adding the previous two terms. By starting with 1 and 2, the first 10 terms will be:
\[1, 2, 3, 5, 8, 13, 21, 34, 55, 89, ...\]By considering the terms in the Fibonacci sequence whose values do not exceed four million, find the sum of the even-valued terms.
Dette problemet kan deles opp i to deler: først må vi finne alle tall i Fibonaccisekvensen som er mindre enn fire millioner, så summerer vi alle av disse som er partall.
For å beregne Fibonaccisekvensen må vi gjøre samme ting (å addere de to forrige tallene) mange ganger. Dette er hva en loop er til for.
Vi vet ikke hvor mange ganger vi må beregne nye tall, vi vet bare at vi skal slutte når vi får et tall som er større enn fire millioner. Derfor bruker vi en while-løkke. Vi må også lagre alle tallene på noen måte. Til dette bruker vi en liste. Så vår kode skal være noe slikt:
fib = [] # Fibonaccisekvensen
fib.append(1) # Vi må ha de første to tallen i sekvensen før løkken
fib.append(2)
while n < 4000000: # n er det seneste tallet i sekvensen
# Beregne neste tall i sekvensen
# Putte tallet i slutten av fib
For å beregne neste tall i sekvensen skal vi addere de to forrige tallene. Derfor må vi hele tiden lagre de to forrige tallene sånn at vi kan bruke dem i neste omgang av løkken. La \(m\) være tallet før \(n\), og la \(l\) være tallet før \(m\). Så for eksempel, i begynnelsen er \(l=1\) og \(m=2\). I neste omgang er \(l=2\) og \(m=3\) etc. Vi bruker så disse for å beregne \(n\) . Vår kode blir da noe slikt:
fib = [] # Fibonaccisekvensen
l = 1
m = 2
fib.append(l) # Vi må ha de første to tallen i sekvensen før løkken
fib.append(m)
n = 0 # n må være definert før løkken
while n < 4000000: # n er det seneste tallet i sekvensen
n = l + m
fib.append(n)
l = m # l og m må oppdateres
m = n
Nå har vi alle tall i Fibonaccisekvensen som er mindre enn fire millioner. Nå må vi beregne summen av alle av disse som er partall.
Her passer det også å bruke en løkke fordi vi vil gå gjennom hele listen
fib og gjøre noe: sjekke om tallet er partall, og (hvis det er et partall) addere
det til summen.
Når vi vil gjøre noe for alle elementer i en liste bruker vi en for-løkke. Koden blir:
fib = [] # Fibonaccisekvensen
l = 1
m = 2
fib.append(l) # Vi må ha de første to tallen i sekvensen før løkken
fib.append(m)
n = 0 # n må være definert før løkken
while n < 4000000: # n er det seneste tallet i sekvensen
n = l + m
fib.append(n)
l = m # l og m må oppdateres
m = n
sum = 0 # Summen må være definert før løkken
for n in fib:
if n % 2 == 0:
sum += n
print(sum) # Sånn at vi får vite hva summen er
Du kan finne hele koden her: eksempel_fibonacci.py.
Diskuter andre løsingsforslag. Kan vi løse oppgaven uten lister? Hva er fordeler / ulemper med ulike løsninger?
Eksempel 3¶
Her skal vi lage en enkel simulasjon av en populasjonsmodell.
På en liten øy finnes \(x=400\) sauer og \(y=20\) ulver. Uten ulver vokser antallet av sauer eksponensielt over tid. Uten sauene forsvinner alle ulvene etter en stund. Når begge finnes på øyen, går antallet ulver litt opp i hvert tidsskritt, og antallet sauer går ned avhengig av hvor mange ulver og sauer det finnes.
I vårt eksempel skal tallene forendres slikt etter et tidsskritt \(\Delta t\):
På hvert tidspunkt vil vi vise hvor mange ulver og sauer vi har. Vi kan bruke
print for å lage et enkel søylediagram ved å skrive ut ulike antall 'x'
og '.' i hvert tidsskritt.
Prøv å skissere en løsning, og diskuter med andre i din gruppe.
Så kan du se på vårt løsningsforslag her: wolf_sheep.py.
(De som er interessert kan finne mer om denne typen ligningssystemer under stikkordet Lotka-Volterra equations. )
Oppgaver¶
Obs
Oppg.1 og 2 er obligatoriske. I tillegg velg to fra oppg. 3, 4 og 5 å levere. Totalt må du levere inn 4 av oppgavene.
Om du vil kjøre pytests lokalt (tilgjengelig for 1,2,4 og 5) kan du laste ned zip-filen her: uke_08_tests.zip
Oppgave 1¶
Pearsons korrelasjonsligning er gitt av:
\((x, y)\) er tidsserier (hver er en liste med målinger) og \((\bar{x}, \bar{y})\) er de tilsvarende gjennomsnittene av hver liste.
I filen uke_08_oppg_1.py implementer Pearsons korrelasjonsligningen som
funksjonen pearson_corr(x,y) som tar som argumenter to lister x og y
og returnerer koeffisienten \(r\) hvor \(-1 \leq r \leq 1\).
Fremgangsmåten:
Ta gjennomsnittet av \(x\) i variabelen
mean_xog \(y\) i variabelenmean_y.Lag listene
dxanddysom inneholder forskjellene \((x_i - \bar{x})\) og \((y_i - \bar{y})\).Multipliser hvert sitt element sin forskjell fra gjennomsnittet i x -listen med forskjellen fra gjennomsnittet i y -listen
dx[i] * dy[i]. Summer disse multipliserte verdiene og lagre dem i variabelensum_dxdy.Obs
TIPPS: Du kan bruke sum() og zip() for å hjelpe med beregningen til produktet av forskjellene for hvert parvis listeelement for å oppsummere disse resultatene.
Lag nye variabler
dx2ogdy2som summen av de kvadrerte forskjellene:dx2\(= \sum_i(x_i - \bar{x})^{2}\) ogdy2\(= \sum_i(y_i - \bar{y})^{2}\).Multipliser
dx2ogdy2og ta kvadratroten til produktet. Lag resultatet i variabelensqr_dx2dy2.Til slutt, beregne korrelasjonskoeffisienten
rsom divisjon avsum_dxdymedsqr_dx2dy2. Variabelenrer resultatet som funksjonen returnerer.
Du kan teste funksjonen din med disse verdiene:
x1_ls = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
y1_ls = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
y2_ls = [1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024]
>>> pearson_corr(x1_ls, y1_ls)
1.0
>>> pearson_corr(x1_ls, y2_ls)
0.7751168025822525
Oppgave 2¶
Måltidsplanlegging for late mennesker
Du hadde en lang dag på skolen og du vil ikke dra til matbutikken på veien hjem. Du vet hva som finnes i kjøleskapet ditt og du har fire måltider som du elsker å lage ofte. Siden du tar INF100 bestemmer du deg for å lage en algoritme som finner de måltidene som du kan lage med det du har i kjøleskapet ditt. Mat i kjøleskapet og måltider er laget til i en liste, f.eks:
# contents of my fridge, in a list
my_fridge = ["tomato sauce", "mustard", "potatoes", "carrots", "chicken", "frozen fish"]
Måltider er laget til en tuple av tupler:
# meals and corresponding ingredients stored in tuple of tuples
meals = (
# name of dish [0], ingredients [1]
("fish_sticks", ("frozen fish", "potatoes", "mustard")),
("chicken_curry", ("chicken", "curry paste", "carrots", "potatoes", "rice")),
("chicken_veg", ("chicken", "potatoes", "carrots")),
("pasta", ("spaghetti", "tomato sauce")),
)
Løs oppgaven i tre steger. I filen uke_08_oppg_2.py gjør følgende:
Implementer en funksjon som heter
meal_list()som tar som input to argumenter: (1) listen av ingredienser i kjøleskapet ditt og (2) tuplen av ingredienser til en måltid. Funksjonen returnererTrue(du har alle ingredienser for å lage måltiden) ellerFalse(du har IKKE alle ingredienser for å lage måltiden). Bruk kodeskissen nedenfor for å komme i gang hvis du vil.
def meal_list(fridge, ingredient_list): """ 1. set up a tally that counts the ingredients you do have for a given meal in your fridge 2. _for each_ ingredient in a meal 3. check _if_ that ingredient is in your fridge 4. _add_ to tally of ingredients for a given meal that are in your fridge 5. once you have looped through the ingredient list, check _if_ your count tally matches the number of items in the ingredient list """ count = 0 # skriv koden her return count == len(ingredient_list)Eksempelkjøring:
>>> meal_list(my_fridge, meals[0][1]) True
Så lag en annen funksjon som heter
meal_options()for å finne måltidene du kan lage med ingrediensene du har i kjøleskapet ditt:
def meal_options(fridge, meals): """ 1. _for each_ tuple pair in meals 2. run meal_list() 3. _if_ function evaluates to `True`, then add to a new list of meals that are possible to make """ meal_options_ls = [] # your code here return meal_options_lsEksempelkjøring:
>>> meal_options(my_fridge, meals) ['fish_sticks', 'chicken_veg']
Til slutt, lag en siste funksjon som heter
to_buy()at for et gitt måltid du ønsker å lage returnerer listen over ingredienser du må kjøpe fra butikken for å lage. Funksjonen tar som input to argumenter: (1) listen av ingredienser i kjøleskapet ditt og (2) tuplen av ingredienser til en måltid.
Obs
TIPPS Strategien for å løse for #3 er lik strategien for #1, med bare små forskjeller.
Eksempelkjøring:
>>> to_buy(my_fridge, meals[3][1]) ['spaghetti']
Oppgave 3¶
I gamle egyptiske tekster finner vi en multiplikasjonsmetode for vilkårlige positive heltall, som fungerer med bare addisjon og dobling.
For å multiplisere for eksempel a = 19 og b = 23, begynner vi med å skrive 1 og doble det til det nye tallet ville vært større enn a:
1
2
4
8
16
Vi stopper på 16, siden 32 er større enn a = 19.
Det finnes nå ett unikt utvalg av disse tallene hvor summen resulterer i a = 19.
Det er 16 + 2 + 1. Vi markerer disse tallene med X.
X 1
X 2
4
8
X 16
I den tredje kolonnen starter vi med tallet b = 23, og fortsetter å doble.
X 1 23
X 2 46
4 92
8 184
X 16 368
Til slutt tar vi bare de tallene fra den siste kolonnen som er merket med X, og summerer dem:
23 + 46 + 368 = 437. Dette er vårt resultat: 19 * 23 er 437.
I uke_08_oppg_3.py skriv et program som gjør følgende:
Spør brukeren om to positive heltall med input().
Ved behov, bytt tallene slik at det første tallet er mindre enn det andre.
Regn ut innholdet til den egyptiske multiplikasjonstabellen etter fremgangsmåten som er vist ovenfor.
Skriv ut den ferdige multiplikasjonstabellen med pen formatering og justerte kolonner; slik at den ser ut som eksemplene vist nedenfor.
For formateringen kan du anta at brukeren bare gir deg tall mellom 1 og 99.
Programmet trenger å kjøre bare en gang hver gang det startes, du trenger ikke å be om nye input etter utskriften.
Noen eksempler på programkjøring ser slik ut:
Factor A: 10
Factor B: 13
=========================
1 13
X 2 26
4 52
X 8 104
=========================
2 + 8 = 10
26 + 104 = 130
=========================
10 * 13 = 130
Factor A: 19
Factor B: 23
=========================
X 1 23
X 2 46
4 92
8 184
X 16 368
=========================
1 + 2 + 16 = 19
23 + 46 + 368 = 437
=========================
19 * 23 = 437
Factor A: 17
Factor B: 6
=========================
1 17
X 2 34
X 4 68
=========================
2 + 4 = 6
34 + 68 = 102
=========================
17 * 6 = 102
Oppgave 4¶
Hordaland har 15 distriktsmandater i Stortinget. Disse 15 mandatene skal fordeles mellom partiene i forhold til stemmetallet de fikk. Metoden er beskrevet slikt i valgloven §11-4 (3):
Hver partiets stemmetall divideres med 1,4 - 3 - 5 - 7 osv. Hvert stemmetall skal divideres så mange ganger som det er nødvendig for å finne det antall mandater listen skal ha. Det første mandatet tilfaller den listen som har den største kvotienten. Det andre mandatet tilfaller den listen som har den nest største kvotienten osv.
Et eksempel på en mandatsfordeling av 11 seter (fra regjeringen.no):
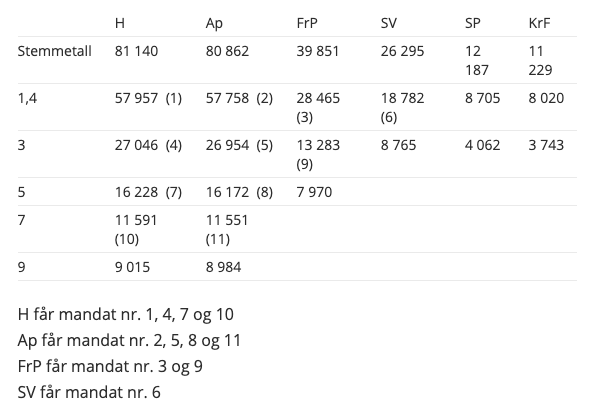
I uke_08_oppg_4.py må du lage 2 funksjoner som bygger på hverandre:
valgresultat(parties, votes, seats),parti_mandater(party_list, votes, seats)
Først lag en funksjon valgresultat(parties, votes, seats)
som tar som argumenter (1) listen av partier, (2) listen med stemmer til hvert parti og
(3) antallet mandater som skal fordeles. Funksjonen skal returnere en liste av seats
tupler som viser kvotienten som float og
partinavnet, f.eks:
parties = ["H", "Ap", "FrP", "SP", "SV", "KrF", "R", "V", "MdG"]
votes = [74282, 68945, 38352, 29981, 26901, 14724, 14150, 13163, 11940]
N_seats = 15
print(valgesultat(parties, votes, N_seats))
[(53058.571428571435, 'H'), (49246.42857142857, 'Ap'), (27394.285714285717, 'FrP'), ... ] # 15 tuples
Så lag en funksjon som heter parti_mandater(party_list, votes, seats)
som igjen tar som argumenter listen av partier, listen av stemmer, og antallet mandater.
Funksjonen skal gjenbruke valgresultat() internt og skal returnere en liste
av tupler som viser partinavn og antallet stemmer og antallet
mandater for hvert parti. Partier uten mandat skal ikke nevnes i tuplen. For
eksempel, resultat i Hordaland gir følgende tuple:
[('H', 74282, 4), ('Ap', 68945, 4), ('FrP', 38352, 2), ('SP', 29981, 2), ('SV', 26901, 1), ('KrF', 14724, 1), ('R', 14150, 1)]
Oppgave 5¶
Oppgaven tilpasset fra 2021 Advent of Code, Day 1: Sonar Sweep
I filen uke_08_oppg_5.py skal du lage to funksjoner: sonar_depth_increase_cnt() og `sonar_depth_increase_cnt_avg() basert på følgende beskrivelser i del 1 og 2 av denne oppgaven.
Obs
Teksten gir alle ledetrådene du trenger for å løse denne oppgaven, så les nøye og så går det helt fint!
Tenk deg at du er en del av et mannskap på en ubåt. Når ubåten faller under havoverflaten utfører den automatisk et sonarsveip av havbunnen i nærheten. På en liten skjerm vises ekkoloddsvei-prapporten (din puslespillinndata): hver linje er en måling av havbunnsdybden når sveipet ser lenger og lenger bort fra ubåten.
Anta for eksempel at du hadde følgende rapport:
"199 200 208 210 200 207 240 269 260 263"
Denne rapporten indikerer at ved å skanne utover fra ubåten fant ekkoloddsveipet dybder på 199, 200, 208, 210, og så videre.
Den første oppgaven er å finne ut hvor raskt dybden øker, bare så du vet hva du har å gjøre med - du vet aldri om nøklene blir båret inn på dypere vann av en havstrøm eller en fisk eller noe.
For å gjøre dette, tell antall ganger en dybdemåling øker fra forrige måling. (Det er ingen måling før den første målingen.) I eksemplet ovenfor er endringene som følger:
199 (N/A - no previous measurement) 200 (increased) 208 (increased) 210 (increased) 200 (decreased) 207 (increased) 240 (increased) 269 (increased) 260 (decreased) 263 (increased)I dette eksemplet er det 7 mål som er større enn den forrige målingen.
I filen
uke_08_oppg_5.pylag en funksjon som hetersonar_depth_increase_cnt()som tar som input dybde-verdiene i en string (se eksempel nedenfor) og returnerer hvor mange målinger er større enn den forrige målingen. Denne funksjonen skal fungere med andre strenger av dybdemålinger, likt som eksemplet vi ga.Eksempelkjøring:
>>> sonar_depths_ticker = "199 200 208 210 200 207 240 269 260 263" >>> sonar_depth_increase_cnt(sonar_depths_ticker) 7
Å vurdere hver enkelt måling er ikke så nyttig som du forventet: det er bare for mye støy i dataen.
Vurder i stedet summen av et skyvevindu med tre mål. Igjen med tanke på eksemplet ovenfor:
199 A 200 A B 208 A B C 210 B C D 200 E C D 207 E F D 240 E F G 269 F G H 260 G H 263 HStart med å sammenligne det første og andre tremålsvinduet. Målene i det første vinduet er merket med A (199, 200, 208); summen deres er 199 + 200 + 208 = 607. Det andre vinduet er merket med B (200, 208, 210); dens sum er 618. Summen av målinger i det andre vinduet er større enn summen av det første, så denne første sammenligningen økte.
Målet ditt nå er å telle antall ganger summen av målinger i dette skyvevinduet øker fra forrige sum. Så sammenlign A med B, sammenlign deretter B med C, deretter C med D, og så videre. Stopp når det ikke er nok mål igjen til å lage en ny tremålssum.
I eksemplet ovenfor er summen av hvert tre-målingsvindu som følger:
A: 607 (N/A - no previous sum) B: 618 (increased) C: 618 (no change) D: 617 (decreased) E: 647 (increased) F: 716 (increased) G: 769 (increased) H: 792 (increased)I dette eksemplet er det 5 summer som er større enn forrige sum.
I filen
uke_08_oppg_5.pylag en funksjon som hetersonar_depth_increase_cnt_avg()som tar dybder-verdiene i en string som input (se eksempel nedenfor), vurder summen av et tre-måls skyvevindu og returner summer som er større enn forrige sum. Denne funksjonen skal fungere med andre strenger av dybdemålinger, likt som eksemplet vi ga.Eksempelkjøring:
>>> sonar_depths_ticker = "199 200 208 210 200 207 240 269 260 263" >>> sonar_depth_increase_cnt_avg(sonar_depths_ticker) 5